Tonclib is coded mostly in C. The reason for this was twofold. First, I still have it in my head that C is lower level than C++, and that the former would compile to faster code; and faster is good. Second, it's easier for C++ to call C than the other way around so, for maximum compatibility, it made sense to code it in C. But these arguments always felt a little weak and now that I'm trying to port tonclib's functions to the DS, the question pops up again.
On many occasions, I just hated not going for C++. Not so much for its higher-level functionality like classes, inheritance and other OOPy goodness (or badness, some might say), but more because I would really, really like to make use of things like function overloading, default parameters and perhaps templates too.
For example, say you have a blit routine. You can implement this in multiple ways: with full parameters (srcX/Y, dstX/Y, width/height), using Point and Rect structs (srcRect, dstPoint) or perhaps just a destination point, using the full source-bitmap. In other words:
void blit(Surface *dst, Point *dstPoint, Surface *src, Rect *srcRect);
void blit(Surface *dst, Point *dstPoint, Surface *src);
In C++, this would be no problem. You just declare and define the functions and the compiler mangles the names internally to avoid naming conflicts. You can even make some of the functions inline facades that morphs the arguments for the One True Implementation. In C, however, this won't work. You have to do the name mangling yourself, like blit, blit2, blit3, or blitEx or blitRect, and so on and so forth. Eeghh, that is just ugly.
Speaking of points and rectangles, that's another thing. Structs for points and rects are quite useful, so you make one using int members (you should always start with ints). But sometimes it's better to have smaller versions, like shorts. Or maybe unsigned variations. And so you end up with:
struct point16_t { s16 x, y; }; // Point as signed short
struct point32_t { s32 x, y; }; // Point as signed int
struct upoint8_t { u8 x, y; }; // Point as unsigned char
struct upoint16_t { u16 x, y; }; // Point as unsigned short
struct upoint32_t { u32 x, y; }; // Point as unsigned int
And then that for rects too. And perhaps 3D vectors. And maybe add floats to the mix as well. This all requires that you make structs which are identical except for the primary datatype. That just sounds kinda dumb to me.
But wait, it gets even better! You might like to have some functions to go with these structs, so now you have to create different sets (yes, sets) of functions that differ only by their parameter types too! AAAARGGGGHHHHH, for the love of IPU, NOOOOOOOOOOOOOO!!! Neen, neen; driewerf neen! >_<
That's how it would be in C. In C++, you can just use a template like so:
struct point_t { T x, y; }; // Point via templates
typedef point_t<u8> point8_t; // And if you really want, you can
// typedef for specific types.
and be done with it. And then you can make a single template function (or was it function template, I always forget) that works for all the datatypes and let the compiler work it out. Letting the computer do the work for you, hah! What will they think of next.
Oh, and there's namespaces too! Yes! In C, you always have to worry about if some other library has something with the same name as you're thinking of using. This is where all those silly prefixes come from (oh hai, FreeImage!). With C++, there's a clean way out of that: you can encapsulate them in a namespace and when a conflict arises you can use mynamespace::foo to get out of it. And if there's no conflicts, use using namespace mynamespace; and type just plain foo. None of that FreeImage_foo causing you to have more prefix than genuine function identifier.
And [i]then[/i] there's C++ benefits like classes and everything that goes with it. Yes, classes can become fiendishly difficult if pushed too far(1), but inheritance and polymorphism are nice when you have any kind of hierarchy in your program. All Actors have positions, velocities and states. But a PlayerActor also needs input; and an NpcActor has AI. And each kind of NPC has different methods for behaviour and capabilities, and different Items have different effects and so on. It's possible to do this in just C (hint: unioned-structs and function-tables and of course state engines), but whether you'd want to is another matter. And there's constructors for easier memory management, STL and references. And, yes, streams, exceptions and RTTI too if you want to kill your poor CPU (regarding GBA/DS I mean), but nobody's forcing you to use those.
So why the hell am I staying with C again? Oh right, performance!
Performance, really? I think I heard this was a valid point a long time ago, but is it still true now? To test this, I turned all tonclib's C files into C++ files, compiled again and compared the two. This is the result:
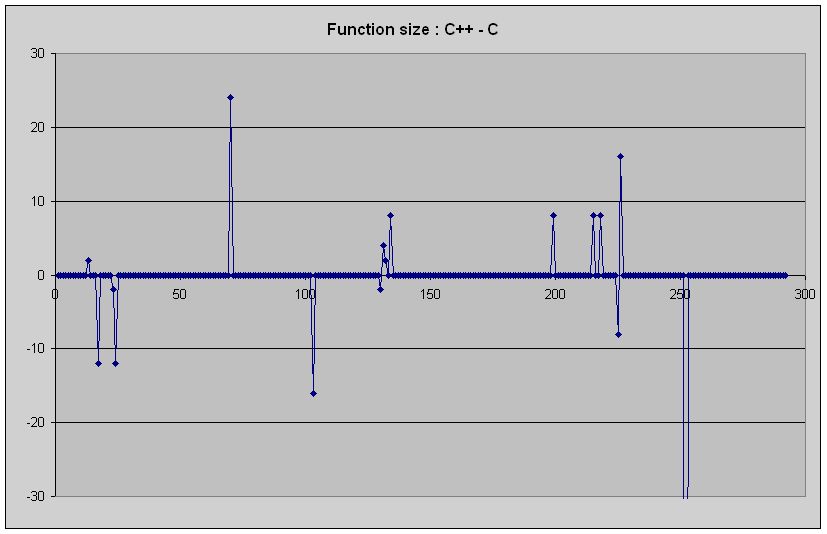
Difference in function size between C++ and C in bytes.
That graph shows the difference in the compiled function size. Positive means C++ uses more instructions. In nearly 300 functions, the only differences are minor variations in irq_set(), some of the rendering routines and TTE parsers, and neither language is the clear winner. Overall, C++ seems to do a little bit better, but the difference is marginal.
I've also run a diff between the generated assembly. There are a handful of functions where the order of instructions are different, or different registers are used, or a value is placed in a register instead of on the stack. That's about it. In other words, there is no significant difference between pure C code and its C++ equivalent. Things will probably be a little different when OOP features and exceptions enter the fray, but that's to be expected. But if you stay close to C-like C++, the only place you'll notice anything is in the name-mangling. Which you as a programmer won't notice anyway because it all happens behind the scenes.
So that strikes performance off my list, leaving only wider compatibility. I suppose that has still some merit, but considering you can turn C-code into valid C++ by changing the extension(2), this is sound more and more like an excuse instead of a reason.
Notes:
- As the saying goes: C++ makes it harder to shoot yourself in the foot, but when you do, you blow off your whole leg.
- and clean up the type issues that C allows but C++ doesn't, like void* arithmetic and implicit pointer casts from void*.
it's not so surprizing that you get almost the same performance if you execute rougly the same code compiled with an other compiler, it would be really interesting to know what will be the difference if you start using c++ specific fonctionality.
elwing: I'm thinking the C++ specific functionality would cause quite a big difference.
yes, but if you cannot use them there is no reason to lose the simplicity to use that library in a pure C project... now I wonder what are the costs of template... doesn't template only takes time at compilation?
[quote]it's not so surprizing that you get almost the same performance if you execute rougly the same code compiled with an other compiler, it would be really interesting to know what will be the difference if you start using c++ specific fonctionality.[/quote]
Yeah, getting the same results for the same code was to be expected, but actually seeing nearly identical results has a stronger impact than just thinking it.
About the difference in C++-specific functionality : testing that can be a little tricky because there might not be a direct C-equivalent of what you're testing. Thinks like function overloading and default parameters does nothing to the function itself, so that will be the same. Simple classes that stick close to C structs (meaning no inheritance and either just members, or members and no constructors) should be roughly the same as well. I'll check this later, but I'd expect something like
object::method(int arg)to be implemented likeobject_method(Object *object, int arg). At that point you simply have an implicit extra pointer argument, and the generated code should be the same.Once you start dealing with explicit constructors/destructors and such, things will probably get a little messier. Creating a C-struct object just allocates memory, but with classes the constructor will be called as well; if that does more than just reserve space, it will cost a little. On the other hand, this is not a fair comparison. If the constructor does more than just reserve space for the object, there's probably a good reason for that; a more proper comparison would be a function call to something like object_init(Object*object). And again, the real difference is that C++ calls this explicitly, where as C requires you to type in the code manually, meaning more work for you.
If you then look at inheritance and polymorphism with virtual functions, abstract classes and all those scary aspects, also keep in mind what the pure-C equivalent would look like. It would involve a lot of duplicated code and functions, or manual casting and dereferencing (with their associated costs) or long chains of member accesses like
derived2.derived1.base.member.[quote cite=elwing]yes, but if you cannot use them there is no reason to lose the simplicity to use that library in a pure C project[/quote]
The thing is, I'm not really seeing any benefit of a pure C project anymore except for legacy purposes. You can write simple code just as well in C++, yet at the same time take advantage of additional functionality (and even simplicity) that C++ brings with it.
[quote] ... now I wonder what are the costs of template... doesn't template only takes time at compilation?[/quote]
Yes. Consider the following:
T min(T a, T b) { return a<=b ? a : b; }
int a=1, b=4, c;
u16 x=3, y=-2, z;
c= min(a, b); uses min<int>. Gives 1
z= min(x, y); uses min<u16>. Gives 3
In this case, the compiler creates two versions of
min(), one forintand one foru16, and both are exactly what they should be. In earlier versions of Tonc I did something similar for the functions OBJ_AFFINE and BG_AFFINE through clever use of #define. It looked horrible, but it kept me from writing the same code twice. A function template would have been ideal.Also, if you inline this function (which actually happens automatically under -O3 and -O2 now too), I still got exactly what I would have expected. It even optimizes it to just c=1 and x=3 in the variables are local.
from my own experience, C and C++ were undistinguishable from each other as long as you do "simple" C++. Templates and name mangling are purely compilation-time techniques, so it will not have much visible effects on the generated code.
One thing that definitely doomed the tininess of my code, however, was stepping into the std:: classes. The smallest vector you add in your code brings on memory management and exceptions processing that involve both runtime overhead and a good +150K of additional code for runtime type checking and similar stuff.
So whether or not you need the extra "++" still remain a matter of personal choice (do you feel like writing 'client' code in C or C++), imvho.
The benchmark and tests you did are very interesting. As many people, I had in my head that "C++ is slower than C, ever".
But personnally, for many projects, I'm sticking to C for a simple reason: it's WAAAAAY faster to compile (at least on my computer).
does that mean that we will get a tonc 1.5 providing various templates and other c++ advantage? :) looks like it's hard to fix and stop updating something...
@thoduv: that was my belief as well, but as sylvain points out, some of the items are really little more than compiler techniques that have little effect on the final code. Still, things like iostream and STL are pretty bloated, so you do need to be careful with those. You could be right about compilation time, but as long at you keep the cross-dependencies low the effects of that can be minimized.
@ elwing: hahaha! Uhm, no. Tonc stays as it is unless someone finds a serious bug. But I think I will go C++ for its successor now, though I'm not sure to what extent just yet.
successor? does that mean you will start a tonc-like project for an other platform? (like the DS?)
Sooooooooo cooooooooool
But how to cvenort a C struct which include pointer field point to a struct?
For example: struct LOCK_IP {
char ip[20];
//lock ipint time;
//lock timefloat a;
//just e.g.double b;
char c;
unsigned char d;
unsigned int e;
struct LOCK_IP* next;
struct someObj* obj;
};
Shall I define the function json_object_new_undefined() by myself ?Thanks
[edit (20140313): added newlines, because gaddamn]
@ Keu,
That's rather off topic, but anyway ...
I'm assuming you mean "how can I make a json object out of a C struct", because converting a C struct to a C struct doesn't make much sense, and the only context you give is the name of some json library function.
The answer is probably: you can't. At least not in any automated sense. I'm assuming you have some sort of json read(/write?) library with functions, but you can't just pass any old struct to some sort of
json_convert()function and get it to work, because that function has no idea what the struct looks like. It seems Jansson has ajson_pack()function that does something like it, but you still have to spell out the members yourself. And if you want pointers, you'll have create the json-object for that pointed-to object first, then add it to the parameter list somehow.In C, you can also create to/from json functions for each struct that convert the data, which you then call at the right moment. In C++ you can do that too, but you can also make (inherited) methods instead so that it happens semi-automatically.